이 문서는
Project Reactor의 공식 참고 문서를 학습 목적으로 번역한 것입니다.
Getting Started
이 섹션은 Reactor를 활용하기 위한 도움을 주는 정보들을 포함하고 있습니다. 이 정보들은 아래 내용을 포함합니다.
- Introducing Reactor
- Prerequisites
- Understanding the BOM
- Getting Reactor
Introducing Reactor
Reactor는 효율적인 요구 관리(demand management, 배압(backpressure)의 형태로 관리되는)를 통해 JVM에 충분한 non-blocking reactive programming 토대를 제공합니다.
Reactor는 CompletableFuture, Stream 그리고 Duration으로 대표되는 Java 8 functional API들을 직접적으로 통합하고 있습니다.
Raactor는 조합 가능한 비동기 sequence API들인 Flux(N개 이상의 요소들)와 Mono(0 혹은 한 개의 요소)를 제공하며, 넓은 의미로 Reactive Streams 스펙을 구현하고 있습니다.
Reactor는 또한 reactor-netty 프로젝트를 통해 프로세스간 non-blocking 통신을 지원하고 있습니다. Micro-Service Architecture에 적합하며, Reactor-Netty는 WebSocket을 포함한 HTTP, TCP 그리고 UDP 통신을 위한 backpressure-ready 엔진을 제공합니다. Reactive encoding과 decoding 또한 충분히 지원합니다.
Reactive encoding/decoding: Reactive Streams back-pressure를 통한 non-blocking I/O로 byte level contents와 상위 레벨의 object간의 직렬화/역직렬화를 지원하는 것을 말하는 것 같습니다.
Prerequisites
Reactor Core는 Java 8 이상에서 동작합니다.
또한 org.reactivestreams:reactive-streams:1.0.2에 이행적인 의존성을 가집니다.
안드로이드 지원:
Reactor 3는 공식적으로 안드로이드를 지원하지 않습니다. RxJava 2를 사용하는 것을 고려 해보세요.- 하지만 안드로이드 SDK 26(Android O)와 그 이상 버전에서의 동작에는 문제가 없습니다.
- 우리는 안드로이드 지원이라는 잇점에 대한 변화를 고려하는 것에 열려 있지만, 그것을 보장할 수는 없습니다. 각각의 경우를 고려하여 결정 되어야 합니다.
Understanding the BOM
Reactor 3는 reactor-core 3.0.4 Aluminium 릴리즈들 이후로부터 BOM 모델을 사용하고 있습니다. 이 나열된 리스트 그룹의 아티팩트들은 함께 잘 동작함을 의미하며, 각각의 아티팩트들에 별도의 버전 관리 체계가 존재하더라도 관련된 버전을 제공합니다.
BOM(Bill of Materials)는 그 자체로 버전 관리되며, 한정자(qualifier) 뒤에 코드네임이 따라오는 release train scheme을 사용합니다. 아래는 몇 가지 예입니다.
Aluminium-RELEASE
Californium-BUILD-SNAPSHOT
Aluminium-SR1
Bismuth-RELEASE
Californium-SR32
코드네임은 전통적인 MAJOR.MINOR 번호로 표현됩니다. 그들은 알파벳순으로 증가하는 주기율표에서 따왔습니다.
한정자들은 시기 순으로 아래와 같습니다.
BUILD-SNAPSHOT
M1..N: 마일스톤 혹은 개발자 프리뷰
RELEASE: 해당 코드네임 시리즈의 첫 GA(General Available) 릴리즈
SR1..N: 해당 코드네임 시리즈의 다음 GA 릴리즈로 Service Release를 나타내고 PATCH number와 동일함
Getting Reactor
초기에 언급 했던 것 처럼, Reactor를 사용하는 가장 쉬운 방법은 BOM을 사용하고 프로젝트에 상응하는 의존성을 추가하는 것입니다. 그러한 의존성을 추가할 때, 반드시 버전을 생략함으로써 BOM으로부터 버전을 획득할 수 있도록 해야 함을 주의합니다.
만약 아티팩트의 특정 버전을 강제하고 싶은 경우에는 버전명을 설정할 수 있숩니다. 또한 BOM 사용을 포기하고 전체 의존성에 아티팩트 버전을 명시할 수도 있습니다.
Maven Installation
BOM의 개념은 기본적으로 Maven 지원에 의한 것입니다. 우선, 아래 코드 조각을 당신의 pom.xml에 추가함으로써 BOM을 import 해야 합니다. 만약 최상위 섹션인 dependencyManagement가 이미 당신의 pom.xml에 존재한다면 contents만 추가하면 됩니다.
1 | |
{1} dependencyManagement 태그를 주의하세요. 이 태그는 기존의 dependencies 섹션에 추가 됩니다.
다음으로, 적절한 Reactor 프로젝트의 의존성을 추가하세요. 보통의 경우 아래와 같이
1 | |
{1} 코어 라이브러리 의존성.
{2} 버전 태그가 존재하지 않습니다.
{3} reactor-test는 reactive streamse에 대한 유닛 테스트 기반을 제공합니다.
Gradle Installation
Gradle은 Maven BOM에 대한 코어 지원이 없지만, Spring의 gradle-dependency-management 플러그인을 사용할 수 있습니다.
우선, Gradle Plugin Portal에 플러그인을 적용하세요.
1 | |
{1} 기술했던 것과 같이, 1.0.6 RELEASE는 플러그인의 최신 버전입니다. 업데이트를 확인 하세요.
그리고 BOM을 import 하기 위해 아래 항목을 추가하세요.
1 | |
마지막으로 버전 넘버 명시 없이 의존성을 추가하면 됩니다.
1 | |
{1} 세 번째(버전) 부분이 없음 : 버전을 위한 부분으로, BOM에서 값을 취하게 됨.
Milestones and Snapshots
마일스톤과 개발자 프리뷰들은 Maven Central 보다는 Spring Milestones repository를 통해 배포 됩니다. 빌드 설정 파일에 추가 하기 위해, 아래 코드 조각을 사용하세요.
Milestones in Maven
1 | |
Gradle의 경우 아래 코드 조각을 사용하면 됩니다.
Milestones in Gradle
1 | |
이와 유사하게, 별도의 지정된 레파지토리에 존재하는 스냅샷의 경우 아래와 같이 적용할 수 있습니다.
BUILD-SNAPSHOTs in Maven
1 | |
BUILD-SNAPSHOTs in Gradle
1 | |
Introduction to Reactive Programming
Reactor는 Reactive Programming 패러다임의 구현체이며, reactive programming은 아래와 같이 요약할 수 있습니다.
Reactive programming은 데이터 스트림과 변화의 전파와 관련된 비동기 프로그래밍(asynchrounous programming) 패러다임입니다. 이는 채택한 프로그래밍 언어를 이용해 정적이거나(ex. 배열) 동적인(ex. event emitter) 데이터 스트림을 쉽게 표현할 수 있음을 의미합니다.
— https://en.wikipedia.org/wiki/Reactive_programming
Reactive programming을 향한 첫 걸음으로써, Microsoft는 .NET 생태계에 Reactive Extensions(Rx) 라이브러리를 만들었습니다. 그리고 RxJava는 JVM 상의 reactive programming을 위해 구현 되었습니다. 시간이 흐르면서, JVM 상에서 reacive library에 대한 인터페이스와 상호작용에 대한 일련의 규격을 정의하는 Reactive Streams라는 노력을 통해 자바 표준화로 나타나게 되었습니다. 이 인터페이스는 Java 9의 Flow 클래스 아래로 통합 되었습니다.
Reactive Programming 패러다임은 종종 객체 지향 언어에서 Observer deisgn pattern의 확장으로서 표현되곤 합니다. 이러한 모든 라이브러리의 Iterable-Iterator 쌍에 대한 이중성이 있으므로, 친숙한 Iterator pattern과 main Reactive Pattern을 비교할 수 있습니다. 이들 간에 가장 주요한 차이점은, Iterator는 pull-based로 동작하는 반면 Reactive Streams는 push-based로 동작한다는 점입니다.
Iterator를 사용하는 것은 값에 접근하는 방법이 전적으로 Iterable에게 달려있음에도 불구하고 명령형(imperative) 프로그래밍 패턴입니다. 순서적으로
언제 next() 아이템에 접근할지를 결정하는 것은 전적으로 개발제의 몫입니다. Reactive Streams에서는 Iteratable-Iterator 쌍에 대응하는 Publisher-Subscriber 쌍이 존재합니다. 그러나 새로운 값이 발생했을 때 그것이 가용함을 Subscriber에게 알리는 것은 Publisher이며, 이러한 push 관점이 reactive 하기 위한 열쇠입니다. 또한 푸시 되는 값들에 대해 적용된 동작들이 명령형 프로그래밍에 비해 선언적으로 표현됩니다. 프로그래머는 정확한 제어 흐름을 나타내는 대신 계산 논리를 표현할 수 있습니다.
값을 푸시하는 것에 더해, 에러 핸들링과 값의 완료 라는 측면은 잘 정의된 방법으로 처리 됩니다. Publisher는 onNext()를 호출함으로써 Subscriber에게 새로운 값을 push 할 수 있고, 또한 onError()를 호출하여 에러 시그널을 보내거나 onComplete() 호출을 통해 완료 시그널을 보낼 수 있습니다. 에러와 완료 모두 sequence를 완료 시킵니다. 이것은 아래와 같이 요약할 수 있습니다.
1 | |
이러한 접근 방식은 매우 유연합니다. 값이 없거나, 하나만 존재하거나, 혹은 n개의 값이 존재하는 경우(무한한 경우도 포함하여)에 대한 유즈 케이스를 모두 설명할 수 있습니다.
그러나 우선 왜 asynchronous reactive 라이브러리가 필요한지 고려해봅시다.
Blocking Can Be Wasteful
현대의 응용 프로그램들은 수 많은 동시적인 유저들에게 도달할 수 있으며, 현대의 하드웨어가 계속해서 발전 함에도 불구하고 소프트웨어의 성능은 여전히 주요한 관심사입니다. 프로그램의 성능을 향상 시키기 위한 두 가지 광범위한 방법이 있습니다.
- paralleize(병렬화): 더 많은 쓰레드와 하드웨어 리소스를 사용합니다.
- 현재의 자원을 더욱 효율적으로 사용할 수 있는 방법을 찾습니다.
보통, Java 개발자들은 blocking code를 통해 프로그래밍합니다. 이는 성능에 대한 병목현상이 있기 전 까지는 별 문제가 되지 않을 것이며, 이 지점에서 추가적인 쓰레드가 고려됩니다. 그러나 자원 활용성의 이러한 확장은 경합과 동싱성 문제들을 빠르게 초래하게 됩니다.
여전히 나쁜 것은, 블록킹 코드가 리소스를 낭비한다는 것입니다. 더욱 자세히 들여다 보면, 프로그램에 D/B에 대한 요청이나 network 호출과 같은 I/O로 인한 동작 지연이 포함 되는 경우, 하나 혹은 그 이상의 쓰레드가 데이터를 기다리기 위해 idle 상태로 전환 되게 되면서 리소스가 낭비 되게 됩니다.
이와 같이 병렬화를 통한 접근은 결코 은탄환이 될 수 없습니다. 이는 하드웨어의 전체 성능에 접근하기 위해 필요하지만, 또한 리소스를 낭비하기 쉬운 복잡한 방법이기도 합니다.
Asynchronously to the Rescue?
두번 째로 언급 했던 접근법인 자원을 더욱 효율적으로 사용할 수 있는 방법을 찾는 것이 자원 낭비 문제에 대한 해결책이 될 수 있습니다. 비동기/논블록킹으로 코드를 작성함으로써, 다른 활성화 된 태스크로 동일한 자원을 사용하여 실행을 전환 시키고 비동기적인 처리가 완료 되면 현재 프로세스로 되돌아올 수 있습니다.
그렇다면 어떻게 JVM 상에서 비동기적인 코드를 작성할 수 있을까요? Java는 비동기 프로그래밍을 위한 두 가지 모델을 제공하고 있습니다:
- Callbacks: 비동기적인 메서드가 리턴 값을 가지지 않고 대신
lambda혹은anonymous class형태의 추가적인callback파라미터를 가집니다. 이 callback은 결과 값이 가용한 경우 호출 됩니다. 이에 대한 잘 알려진 예로Swing의EventListener계층 구조가 있습니다. - Futures: 비동기 메서드가 즉시
Future<T>를 리턴합니다. 비동기 프로세스가 T 값을 계산하고, 대신Future객체가 이를 감싸게 됩니다. 즉시 값이 가용하지 않으면Future객체를 통해 값이 유효할 때 까지 polling 할 수 있습니다. 그 예로,Future오브젝트를 이용한Callable<T>태스크를 실행하는ExecutorService가 있습니다.
이러한 방법들로 충분할까요? 이러한 접근들이 모든 유즈 케이스에 대해 충분한 것은 아니며, 두 방법 모두 제약사항을 가지고 있습니다.
Callback은 함께 조합하기 어려우며, 코드 가독성과 유지보수성을 빠르게 떨어뜨립니다. (콜백 지옥으로 알려진)
다음 예제를 통해 생각해봅시다: 사용자 UI로부터 상위 다섯개의 즐겨찾기를 표시하고, 존재하지 않는 경우에는 제안 사항을 표시합니다. 이것은 세 개의 서비스(1. 즐겨찾기 ID 제공, 2. 즐겨찾기 상세 내용 제공, 3. 제안 사항에 대한 상세 내용 제공)를 통해 이루어 집니다.
Example of Callback Hell
1 | |
{1} Callback 기반의 서비스: 비동기 실행이 성공하였을 때에 대한 메서드와 에러 케이스에 대한 메서드를 가지는 Callback interface.
{2} 첫 번째 서비스가 즐겨찾기 ID리스트로 콜백을 호출합니다.
{3} 만약 리스트가 비어 있을 경우, suggestionService를 호출해야 합니다.
{4} suggestionService는 두 번째 콜백에 List<Favorite>를 제공합니다.
{5} 우리가 UI를 다루고 있기 때문에, 데이터를 소비하는 코드가 UI thread에서 동작함을 보장해야 합니다.
{6} 제안 사항의 수를 다섯 개로 제한하기 위해 Java 8 Stream을 사용하고, UI에 가시적인 리스트로 표현합니다.
{7} 각 단계에서 에러는 같은 방법으로 핸들링합니다: 팝업 띄우기
{8} 즐겨찾기 ID 단계로 돌아가서, 만약 서비스가 전체 리스트를 리턴한 경우 Favorite 객체의 상세 정보를 획득하기 위해 favoriteService로 가야 합니다. 우리는 단지 다섯 개의 결과만을 원하기 때문에 우선 리스트의 스트림을 다섯 개로 제한합니다.
{9} 또, 콜백입니다. 이번에는 UI 쓰레드의 UI에 푸시하기 위한 모든 정보를 가진 Favorite 객체를 얻습니다.
상당한 양의 코드입니다. 이러한 코드는 따라가기도 어렵고 반복되는 코드가 존재합니다. Reactor를 이용한 동일한 동작의 코드를 봅시다.
Example of Reactor code equivalent to callback code
1 | |
{1} 즐겨찾기 ID의 flow로 시작합니다.
{2} 즐겨찾기 ID를 자세한 Favorite 객체로 비동기적인 변환(flatMap)을 시도합니다. 이제 Favorite의 flow를 가집니다.
{3} Favorite flow가 비어있는 경우, suggestionService를 통한 fallback으로 전환합니다.
{4} 오직 최대 다섯 개의 결과에만 관심이 있습니다.
{5} 최종적으로 각각의 데이터 조각이 UI thread에서 처리 되기를 원합니다.
{6} 데이터의 최종형태를 위해 해야하는 것과 에러 케이스일 때 해야 하는것에 대해 정의 함으로써 이 flow를 트리거링합니다.
즐겨찾기 ID가 800ms 미만에서만 검색 되도록 하고, 처리 시간이 초과되는 경우 cache에서 가져오도록 하려면 어떻게 해야할까요? Callback 기반으로는 복잡한 작업이지만, Reactor를 이용하면 method chain에 timeout operator를 추가하는 것 처럼 쉽게 할 수 있습니다.
Example of Reactor code with timeout and fallback
1 | |
{1} 윗 부분(userService.getFavorite())에서 800ms 동안 아무런 아웃풋이 없을 경우 에러를 전파합니다.
{2} 에러 케이스인 경우, cacheService로 fall back 합니다.
{3} 이후의 method chain은 이전 예제와 유사합니다.
Future는 Callback에 비해 꽤 낫지만, CompletableFuture에 의해 Java 8에서 개선 되었음에도 불구하고 여전히 잘 구성하기 어렵습니다. 여러 Future를 함께 운용하는 것은 가능하지만 쉽지 않습니다. 또한, Future는 다른 문제점을 가지고 있습니다. Future는 get() 메서드 호출로 인한 또 다른 블로킹 상황을 초래하기 쉬우며, 느린 수행(lazy-computation)을 지원하지 않고, 다중 값들 또는 에러들에 대한 지원이 부족합니다.
또 다른 예제를 봅시다: 우리는 이름과 통계 정보 쌍을 조합하기 원하는 ID의 리스트를 얻고, 모든 것은 비동기적으로 이루어집니다.
Example of CompletableFuture combination
1 | |
{1} 처리해야 할 ID list를 제공하는 Future로 시작합니다.
{2} 일단 목록을 얻게 되면 좀 더 깊은 단계의 비동기적인 처리를 시작합니다.
{3} 리스트의 각 요소에 대해:
{4} 비동기적으로 관련된 이름을 획득합니다.
{5} 비동기적으로 관련된 통계를 획득합니다.
{6} 두 CompletableFuture의 결과를 조합합니다.
{7} 이제 모든 조합 작업을 나타내는 Future의 리스트를 가집니다. 이러한 작업을 수행하기 위해 리스트를 배열로 변환합니다.
{8} 모든 태스크들이 완료 되었을 때 완료 Future를 아웃풋으로 가지는 CompletableFuture.allOf()로 배열을 전달합니다.
{9} allOf()가 CompletableFuture<Void>를 리턴하기 때문에, join()을 통한 결과 수집을 하기 위해 Future의 리스트를 다시 반복 해야합니다. allOf()가 모든 Future가 이루어지는 것을 보장하기 때문에 여기서 블록 되지는 않습니다.
{10} 일단 모든 비동기 파이프라인이 트리거 되면, 이것이 처리되는 것을 기다리고 우리가 assertion할 수 있도록 결과의 리스트를 리턴합니다.
Reactor가 더 많은 조합 연산자들을 기본적으로 가지고 있기 때문에, 전체적인 과정이 더욱 단순해집니다.
Example of Reactor code equivalent to future code
1 | |
{1} 이번에는 비동기적으로 제공되는 sequence인 Flux<String>으로 시작합니다.
{2} Sequence의 각 요소에 대해 비동기적으로 두 번 처리합니다. (flatMap()을 호출하는 함수 내부에서)
{3} 관련 이름을 획득합니다.
{4} 관련 통계를 획득합니다.
{5} 비동기적으로 두 값을 조합합니다.
{6} 값이 가용하면 리스트로 값을 집계합니다.
{7} 상용화 단계라면 Flux를 더 많이 결합하거나 구독함으로써 비동기식으로 작업할 것입니다. 대부분의 경우 Mono를 결과로 리턴하게 됩니다. 지금은 테스트이기 때문에, 블록 시키고 처리가 완료 되기를 기다린 후 집계 된 값의 리스트를 직접 반환합니다.
{8} 결과를 확인합니다.
Callback과 Future의 비슷한 위험서을 가지며, 이것이 Reactive Programming이 Publisher-Subscriber 쌍과 함께 해결하고자 하는 부분입니다.
From Imperative to Reactive Programming
Reactor와 같은 reactive library들은 JVM 생태계의 전통적인 비동기적 접근들이 가지는 아래와 같은 단점들을 해결하면서 그와 함께 몇 가지 추가적인 측면에 집중하고 있습니다 :
- 조합성과 가독성
- 풍부한 표현력을 가진
operator들로 다루어지는 flow로서의 data - 구독(
subscribe) 전 까지는 아무것도 발생하지 않음 - 배압(
backpressure) 또는 데이터 생성률이 과도하지 않도록 생산자(publisher)에게 소비자(consumer`)가 신호를 보낼 수 있는 능력 - 고 수준이지만 너무 추상적이지 않은 동시성
Composability and Readability
조합성(compsability)이란 다수의 비동기 작업들을 조율하고, 이전 작업의 결과를 사용하여 후속 작업의 입력으로 사용하거나 fork-join 스타일로 일련의 작업을 수행함과 동시에 고수준의 시스템에서 비동기 작업들을 구체적인 구성 요소로서 재사용함을 의미합니다.
태스크들을 조율하기 위한 능력은 코드의 가독성과 유지 보수 용이성에 큰 연관이 있습니다. 비동기 프로세스 레이어들이 코드의 양과 복잡성을 증가 시키면서 코드를 조합하고 읽는 것에 대한 어려움은 점점 증가하고 있습니다. 우리가 보았듯이 callback 모델은 단순하지만 이 모델의 가장 큰 단점은 복잡한 프로세스들에 대해 하나의 콜백에서 또 다른 콜백을 실행할 필요가 있으므로 콜백과 같은 것들을 중첩 시켜야 한다는 점입니다. 그러한 복잡함은 콜백 지옥(Callback Hell)로 알려져 있습니다. 추측 해보거나 혹은 경험적으로 이러한 코드는 가독성이 매우 떨어지게 됩니다.
Reactor는 풍부한 조합 옵션들을 제공하여 코드가 추상화된 프로세스를 반영하고 모든 것을 일반적으로 동일한 수준에 유지할 수 있게 해줍니다. (중첩의 최소화)
The Assembly Line Analogy
Reactive application에서의 데이터 처리를 조립 라인에서의 움직임으로 생각 해볼 수 있습니다. Reactor는 컨베이어 벨트와 작업장 모두와 유사한 개념입니다. 원산지(Publisher)로부터 발생 되는 원자재는 최종 제품으로서 소비자(Subscriber)에게 전달 될 준비를 합니다.
원자재는 다양한 변환 과정과 서로 다른 중간 과정 또는 중간 산출물들을 집계하는 더 큰 조립라인의 일부가 되어 진행 됩니다. 만약 예기치 않은 고장이 발생하거나 특정 부분에서 정체가 발생한다면(아마도 제품을 포장하는 부분에서 과도하게 오랜 시간이 걸리듯) 밀려있는 작업이 쌓인 작업장은 원자재의 흐름을 제한하기 위해 생산순서의 상위로(upstream) 신호를 보낼 수 있습니다.
Operators
Reactor에서 operator들은 우리의 조립라인에서의 작업장에 비유할 수 있습니다. 각각의 operator들은 Producer에게 어떠한 행위를 추가하고 이전 단계의 Producer를 새로운 인스턴스로 감쌉니다. 이러한 전체 과정은 연결되고, 최초의 Publisher로부터 유래한 데이터는 연결 고리를 따라 내려가며 각각의 연결에 의해 변환됩니다. 결국 Subscriber가 전체 과정을 완료합니다. 곧 살펴 보겠지만 Subscriber가 구독(Subscribe) 하지 않는 한 아무 일도 일어나지 않음을 기억하세요.
각각의
Operator가 새로운 instance를 생성한다는 점을 기억하는 것은 당신이 사용한Operator가 당신의 전체 과정에 아무것도 적용하지 않는 다는 매우 흔한 실수를 방지하는 것에 도움을 줄 수 있습니다. FAQ내의 이 링크를 확인하세요.
Nothing Happens Until You subscribe()
Reactor에서 Publisher operator chain을 구성했을 때, 기본적으로 데이터는 발생을 시작하지 않습니다. 이것은 대신 비동기 프로세스에 대한 추상적인 설명(재사용하고 조합하는 것에 도움이 되는)을 생성했음을 의미합니다.
구독(Subscribing)을 함으로써 Publisher와 Subscriber를 서로 묶고 전체 operator chain에서의 데이터 흐름을 시작하게 할 수 있습니다. 이는 내부적으로 Subscriber로부터의 한 request 신호를 통해 이루어지며 이는 최초의 데이터 source인 Publisher에게로 chain을 거슬러 올라가 전달됩니다.
Backpressure
상위로 신호를 전달하는 것은 또한 Backpressure를 구현하는 것에도 사용됩니다. 이는 조립 라인의 예제에서 작업장이 적체된 작업으로 인해 상위 작업장으로 원자재 흐름에 대한 조정 신호를 보내는 것으로 비유 되었었습니다.
Reactive Streams 스펙에 의해 정의된 실제 동작 방식은 이 비유와 매우 유사합니다: Subscriber는 unbounded mode로 동작할 수 있고, 데이터 소스가 모든 데이터를 최대 속도로 push하도록 하거나 또는 request 동작 방식을 사용해 최대 n개의 요소를 처리할 준비가 되었음을 알릴 수 있습니다.
중간 Operator들은 중간 처리 과정에서 요청을 바꿀 수도 있습니다. 10개의 batch 작업 요소를 그룹화 하는 buffer operator가 있다고 상상해봅시다. Subscriber가 하나의 버퍼를 요청하면, 이는 data source가 10개의 요소를 생성하는 것을 받아들일 수 있습니다. 어떤 운영자는 request(1)을 매 번 요청 하는 것을 피하는 prefetching전략을 구현할 수도 있고, 이는 요청 하기 전에 요소들을 미리 생성하는 비용이 크지 않은 경우 유용할 수 있습니다.
이는 push model을 push-pull hybrid로 변환하며, downstream 그것들이 준비되어 있을 경우 upstream으로부터 n개의 요소를 pull 할 수 있게 됩니다. 그러나 만약 요소들이 준비 되지 않은 상태라면 각각의 요소들이 생성 될 때 마다 upstream에 의해 push 됩니다.
Hot vs Cold
Rx와 같은 reactive library에서는 reactive sequence를 크게 두 가지 카테고리로 구분할 수 있습니다: hot 그리고 cold 입니다. 이러한 구분은 주로 reactive stream이 Subsriber에 어떻게 반응해야 하는지에 대한 특징으로 나누게 됩니다.
Coldsequence는 각각의Subscriber에 대해 시작하며, 이는 데이터의 source를 포함합니다. 예를 들어, 만약 데이터 소스가 HTTP call을 감싸고 있다면 새로운 HTTP request가 각각의Subscription에 대해 생성 됩니다.Hotsequence는 반대로 각각의Subscriber에 대해 처음부터 시작하지 않습니다. 대신, 늦은Subscriber는 그들이 구독을 시작한 이후의 signal 부터 수신하게 됩니다. 하지만 몇몇Hot reactive stream들은 발생한 이벤트들의 이력을 일부 혹은 전체를 캐싱할 수도 있음을 주의하세요. 일반적인 관점으로는Hotsequence는 구독 중인Subsriber가 없을 때에도 signal을 발생 시킬 수 있으며, 이는구독 하기 전에는 아무 일도 발생하지 않는다라는 룰의 예외입니다.
Reactor에서의 Hot vs Cold에 대한 자세한 정보는 reactor-specific section에서 확인 할 수 있습니다.
Reactor Core Features
The Reactor Project의 메인 구성요소는 reactor-core로, Reactive Streams 스펙에 중점을 두고 Java 8을 타겟으로 하는 reactive library입니다.
Reactor는 Publisher를 구현하면서도 풍부한 표현력을 가진 Operator를 제공하는 조합 가능한 reactive type인 Flux와 Mono를 제안하고 있습니다. Flux object는 0..N(0개에서 N개)의 아이템으로 구성되는 reactive sequence를 나타내는 반면, Mono object의 경우 singlie-value-or-empty(0..1) 결과를 나타냅니다.
이러한 구분은 타입에 의미적인 정보를 이끌어내며, 비동기 프로세스의 수량을 러프하게 지칭합니다. 예를 들어 HTTP 요청은 오직 하나의 응답을 생성하므로 count 연산을 하는 것은 자연스럽지 않습니다. 이러한 HTTP 요청의 결과를 Mono<HttpResponse>와 같이 표현할 수 있고 이는 0개 또는 하나의 아이템을 가진다는 맥락에 상응하는 Operator만들 제공하므로 Flux<HttpResponse> 라는 표현보다 훨씬 매끄럽게 됩니다.
처리 과정에서 최대 cardinality를 변경 하는 Operator는 관련 타입 또한 전환 시킵니다. 예를 들어 Flux 타입에 존재하는 count 연산자는 Mono<Long>을 반환하게 됩니다.
Flux, an Asynchronous Sequence of 0-N Items

Flux<T>는 0개에서 N개의 아이템을 생성하는 비동기 sequence를 나타내는 표준 Publisher<T> 이며, 부수적으로 완료(completion) 혹은 에러(error) 시그널로 종료 될 수 있습니다. Reactive Streams 스펙에 따라, 이러한 세 가지 형태의 시그널은 Subscriber의 onNext(), onComplete(), onError() 메서드에 대한 호출로 변환됩니다.
이러한 시그널들로 넓은 범위를 커버할 수 있기 때문에 Flux는 범용(general-purpose) reactive type입니다. 종료 시그널을 포함하는 모든 이벤트들은 선택 사항이라는 것을 기억하세요: onNext이벤트가 없는 onComplete 이벤트는 빈(empty) 유한 sequence를 의미하며, 여기서 onComplete이벤트를 제거한다면 이것은 무한한(infinitie) empty sequence(취소와 관련된 테스트를 제외하면 별로 유용하진 않지만)를 표현할 수 있습니다. 비슷하게, 무한 sequence들은 비어있을 필요는 없습니다. 예를 들어, Flux.interval(Duration)은 clock을 이용해서 일정 tick마다 Flux<Long>를 무한히 생성해냅니다.
Mono, an Asynchronous 0-1 Result
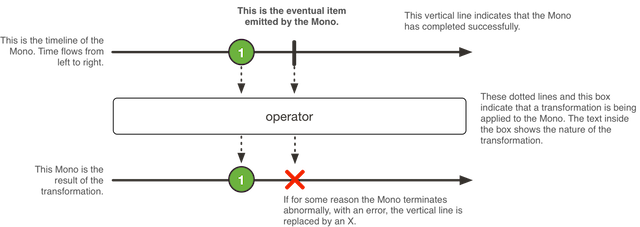
Mono<T>는 0개 혹은 최대 한 개의 아이템을 생성하기 위한 특수한 형태의 Publisher<T>이며, 선택적으로 onComplete 혹은 onError 시그널들을 통해 종료됩니다.
Mono에는 Flux에 적용 가능한 Operator들의 부분 집합만을 제공하며, 몇몇 Operator들은(특히 Mono와 다른 Publisher를 결합하는 것들) Flux로 전환시키기도 합니다.
얘를 들어, Mono#concatWith(Publisher)는 Flux를 반환하는 반면, Mono#then(Mono)는 또 다른 Mono를 반환합니다.
Runnable과 유사하게 Mono는 값을 가지지 않고 오직 완료의 개념만을 가지는 비동기 프로세스들을 나타내기 위해 사용할 수 있습니다. 그러한 비어있는 Mono를 생성하기 위해 Mono<Void>를 사용할 수 있습니다.
Simple Ways to Create a Flux or Mono and Subscribe to It
Flux와 Mono를 시작하는 가장 쉬운 방법은 그들 각각의 클래스들에 속해있는 수많은 팩토리 메서드들 중 하나를 사용해보는 것입니다.
예를 들면, String sequence를 생성하기 위해서는 아래 예제와 같이 그 요소들을 나열하거나, 혹은 그들을 컬렉션에 넣고 그로부터 Flux를 생성할 수 있습니다:
1 | |
팩토리 메서드에 대한 또 다른 예제는 아래와 같습니다:
1 | |
{1} 팩터리 메서드는 값이 없는 경우에도 제너릭 타입을 사용하고 있음을 유의하세요.
{2} 첫 번째 파라미터는 값의 범위에 대한 시작 값을 나타내는는반면, 두 번째 파라미터는 생성할 아이템의 갯수입니다.
이 sequence가 구독되고 있을 때, Flux와 Mono는 Java 8 Lambdas를 사용하게 됩니다. 아래와 같은 Subscribe 메서드의 시그니처에서 볼 수 있듯, 서로 다른 조합의 콜백들을 나타내는 lambdas를 가지도록 선택 가능한 다양한 형태의 .subscribe()가 있습니다.
1 | |
{1} sequence를 구독하고 트리거합니다.
{2} 각각의 생성 된 값에 대해 어떠한 행위를 수행합니다.
{3} 생성 된 값을 다루면서도 에러가 발생했을 때 반응합니다.
{4} 생성 된 값과 에러를 다루면서 sequence가 성공적으로 완료 되었을 때 특정 코드를 수행합니다.
{5} 생성 된 값과 에러, 그리고 성공적인 완료를 다루면서 이 subscribe 콜로 생성한 Subscription을 이용해 특정 행동을 수행합니다.
이러한
subscribe의 여러 변형들은 더 이상 데이터가 필요 없을 경우 구독을 취소하는데 사용할 수 있는Subscription의 레퍼런스를 반환합니다.
일단 취소하게 되면, 데이터 소스는 값의 생성을 중지해야 하며, 이미 생성된 값에 대해서는 클린업 동작을 수행해야 합니다.
Reactor내에서 이러한 취소와 클린업 동작은 범용 목적의Disposable인터페이스로 표현됩니다.
subscribe Method Examples
이 섹션은 subscribe 메서드의 다섯 가지 시그니처 각각에 대한 최소한의 예제를 담고 있습니다. 다음의 코드는 아무런 매개 변수가 없는 가장 기본적인 메서드를 보여줍니다.
1 | |
{1} Subscriber가 붙었을 때 세 개의 값을 생성하는 Flux를 설정합니다.
{2} 가장 단순한 방법으로 구독을 시작합니다.
위 코드는 가시적인 아웃풋을 생성하지 않지만 동작하긴 합니다. Flux는 세 개의 값을 생성합니다. 만약 lambda를 제공한다면 생성하는 값을 가시적으로 만들 수 있습니다. 아래의 예제는 subscribe 메서드가 생성하는 값을 보여주는 방법 중 하나입니다:
1 | |
{1} Subscriber가 붙었을 때 세 개의 값을 생성하는 Flux를 설정합니다.
{2} 값을 출력하는 subscriber를 이용해 구독합니다.
위 코드는 아래와 같은 아웃풋을 생성합니다:
1 | |
다음 시그니처에 대한 시연을 위해 아래와 같이 의도적으로 에러를 발생시키도록 해보겠습니다:
1 | |
{1} Subscriber가 붙었을 때 세 개의 값을 생성하는 Flux를 설정합니다.
{2} 각각의 값들을 다른 방식으로 처리하기 위해 map이 필요합니다.
{3} 대부분의 값은 그 값을 반환하도록 합니다.
{4} 특정 값의 경우 강제로 error를 발생 시킵니다.
{5} error handler를 포함하는 Subscrier를 통해 구독을 시작합니다.
두 개의 람다 표현식을 가지고(예상하고 있는 컨텐트를 위한 것 하나와, 에러를 위한 것 하나) 아래와 같은 결과를 출력하게 됩니다.
1 | |
다음으로 살펴볼 subscribe메서드의 시그니처는 아래 예제와 같이 에러 핸들러와 완료 이벤트 핸들러를 포함하고 있습니다:
1 | |
{1} Subscriber가 붙었을 때 세 개의 값을 생성하는 Flux를 설정합니다.
{2} 완료 이벤트 핸들러를 가지는 Subscriber를 이용해 구독을 시작합니다.
에러 시그널과 완료 시그널 모두 종료(terminal) 이벤트이고 두 이벤트 모두 서로에 대해 베타적으로 동작(절대로 두 이벤트 모두를 받을 수 없음)합니다. 완료 이벤트에 대한 Consumer를 동작 시키기 위해, 반드시 에러를 트리거 하지 않도록 신경써야 합니다.
완료 시그널에 대한 콜백은 람다 표현식에서 빈 괄호로 표현 된 것처럼 아무런 입력을 받지 않으며, 이는 Runnable interface의 run메서드와 일치합니다. 위 코드는 아래와 같은 아웃풋을 생성합니다.
1 | |
마지막으로 살펴 볼 subscribe 메서드의 시그니처는 Consumer<Subscription>을 포함하고 있습니다. 이 시그니처는 Subscription을 이용해 수행할 동작(request(long) 혹은 cancel()을 실행)을 필요로 하며, 그렇지 않을 경우 Flux를 멈추게(hang) 됩니다:
1 | |
{1} 구독을 시작하면 Subscription을 전달 받습니다. 10개의 요소를 요구하는 시그널을 요청하지만(request(10)) 실제 생성 되는 요소는 네 개 이므로 네 개의 요소를 처리하고 완료 됩니다.
Canceling a subscribe() with its Disposable
이러한 람다 기반의 subscribe() 변형들은 모두 Disposable 반환 타입을 가집니다. 이 경우 Disposable 인터페이스는 이 Subscription에 대해 dispose() 메서드를 호출 함으로써 cancel 가능함을 나타냅니다.
Flux와 Mono의 경우, cancellation은 데이터 소스에게 요소 생성을 멈추라는 시그널입니다. 하지만 이것이 즉시 수행됨을 보장하지는 못합니다: 몇몇 데이터 소스들은 매우 빠르게 요소들을 생성하여 취소 요청을 수신하기 전에 이미 모든 요소를 생성할 수도 있습니다.
Disposable 클래스에서 제공하는 몇몇 유틸리티 중에서 Disposable.swap()은 Disposable의 구현체를 원자적으로(atomically) 취소하고 새로운 것으로 대체 시킬 수 있는 wrapper를 생성합니다. 이것은 매우 유용한데, 예를 들어 유저가 버튼을 클릭할 때 마다 현재의 요청을 취소 시키고 새로운 요청으로 대체하는 UI 시나리오가 있습니다. Wrapper 자체를 폐기하는 것은 현재의 구체적인 값과 미래 시점에서 시도 되는 모든 대체 동작들을 닫게 합니다.
또 하나의 흥미로운 유틸리티로는 Disposable.composite(...)가 있습니다. 이 composite는 서비스 요청에 관련 있는 다수의 임시 요청과 같은 여러 Disposable들을 수집하고 나중 시점에 한 번에 처리할 수 있습니다. 일단 composite의 dispose()메서드가 호출 되면, 또 다른 Disposable을 추가하려는 시도가 즉시 처리됩니다.
Alternative to lambdas: BaseSubscriber
람다들을 조합하는 것 보다 더욱 일반적이고 본격적인 구독자를 가지는 추가적인 subscribe 메서드가 존재합니다. Subscriber를 작성하는 것을 돕기 위해 BaseSubscriber라는 확장 가능한 클래스를 제공합니다.
이 중 하나를 구현 하고 이를 SampleSubscriber라고 부릅시다. 아래 예제는 어떻게 Flux와 연동하는지를 보여줍니다:
1 | |
이제 최소한의 BaseSubscriber 구현체를 통해 SampleSubscriber가 무엇인지 살펴보겠습니다:
1 | |
SampleSubscriber 클래스는 BaseSubscriber 클래스를 상속하는데, 이는 Reactor에서 user-defined Subscriber를 위해 추천하는 추상 클래스입니다. 이 클래스는 Subscriber의 행위를 튜닝하기 위해 오버라이딩 될 수 있는 hook들을 제공하고 있습니다. 기본적으로 제한없는 요청을 트리거하고 subscibe()와 완전히 동일하게 동작합니다. 하지만 BaseSubscriber를 확장하는 것은 요청의 수를 조정하고 싶을 때 더욱 유용합니다.
요청의 수를 조정하기 위해, 위 코드에 구현했던 것과 같이 hookOnSubscribe(Subscription subscription)과 hookOnNext(T value)를 구현하기만 하면 됩니다. 위 예제에서는 hookOnSubscribe 메서드는 표준 출력으로 문장을 출력하고 첫 번째 요청을 만듭니다. 그리고 나면 hookOnNext 메서드가 문장을 출력하고 한 번에 하나씩 추가적인 요청을 생성합니다.
SampleSubscriber클래스의 수행 결과는 아래와 같습니다:
1 | |
BaseSubscriber는 또한 unbounded mode로 전환할 수 있게 requestUnbounded() 메서드(request(Long.MAX_VALUE)와 동일한 의미)를 제공하며 또한 cancel() 메서드도 제공합니다.
추가적인 hook으로 hookOnComplete, hookOnError, hookOnCancel 그리고 hookOnFainally(sequence가 종료될 때 SignalType 파라미터로 타입을 전달하며 항상 호출되는)가 있습니다.
hookOnError,hookOnCancel및hookOnComplete메서드를 구현하기 원할 것입니다. 그리고hookFinally를 구현하기를 원할지도 모릅니다.SampleSubscribe는 제한된 요청을 수행하기 위한Subscriber의 최소한의 구현입니다.
On Backpressure, and ways to reshape requests
Reactor에서 backpressure를 구현할 때, Consumer pressure는 업스트림 operator에게 request를 전송함으로써 데이터 소스까지 거꾸로 전달해 나가는 것입니다. 현재 요청의 합계는 종종 지금의 “요구” 혹은 “지연된 요청”으로 참조됩니다. 요구는 제한 없는 요청(“가능한 빠르게 생상하라”와 같이 기본적으로 backpresuure를 비활성화 시키는)인 Long.MAX_VALUE로 나타납니다.
최초의 요청은 최종 구독자의 구독 시점에서 발생하지만, 모든 것을 즉시 구독하는 가장 직접적인 방법은 Long.MAX_VALUE의 무제한 요청을 트리거 하는 것입니다:
subscribe()와 람다 기반의 변형들 중 대부분(Consuner<Subscription>을 가지는 예외를 제외한)block(),blockFirst()그리고blockLast()toIteraable()/toStream()을 순회 하는 것
기존 요청을 커스터마이징 하는 가장 단순한 방법은 hookOnSubscribe 메서드를 오버라이드한 BaseSubscriber와 함께 subscribe하는 것입니다:
1 | |
위 코드 조각은 아래와 같은 결과를 출력 합니다:
1 | |
요청을 다룰 때, 시퀀스를 진행 시킬 수 있을 정도로 충분히 요청 하도록 주의해야 합니다. 그렇지 않을 경우
Flux는 곧막히게(stuck)됩니다. 이것이BaseSubscriber가 기본적으로 무제한의 요청을 하는 이유입니다. 이 hook을 오버라이드 할 때, 최소한 한 번은 요청을 호출 해야합니다.
Operators changing the demand from downstream
한 가지 명심해야 할 것은 구독 수준에서의 요구(demand)는 업스트림 체인의 각 오퍼레이터들에 의해 재구성(reshaped)될 수 있음을 표현한다는 것입니다. buffer(N) 오퍼레이터인 textbook의 경우: 만약 request(2)를 요청 받았을 경우 두 개의 full buffer에 대한 요구로 해석합니다. 그 결과, buffer는 full 상태를 구성하기 위해 N개의 요소를 필요로 하므로, buffer 오퍼레이터는 2 x N에 대한 요청으로 재구성됩니다.
아마 몇몇 오퍼레이터들은 prefetch라고 불리는 int 타입의 입력 파라미터를 가지는 변형이 있음을 알아 차렸을 수 있습니다. 이것은 오퍼레이터에 대한 또 다른 범주로 다운스트림 요청을 변형하는 것입니다. 이 오퍼레이터들은 내부 시퀀스를 다루며, 도달하는 각 요소(flatMap과 같이)에서 Publisher를 파생합니다.
Prefetch는 이러한 내부 시퀀스에서 생성 된 최초의 요청을 튜닝하는 방법입니다. 만약 명시 되지 않은 경우 대부분의 이러한 오퍼레이터들은 32의 요청을 기본으로 시작합니다.
이러한 오퍼레이터들은 보통 replenishing optimization(보충 최적화)를 구현합니다: 일단 오퍼레이터가 25%의 prefetch 요청을 만족하면, 업스트림으로부터 다시 나머지 25%를 재요청합니다. 이는 직관적인(heuristic) 최적화로 이러한 오퍼레이터들이 앞으로의 요청을 사전에 예측할 수 있도록 합니다.
최종적으로, 이 두 오퍼레이터들은 요청을 직접적으로 튜닝할 수 있도록 하기 위해 만들어졌습니다: limitRate와 limitRequest입니다.
limitRate(N)은 다운스트림 요청을 분할하여 더 작은 배치(batch)들로 업스트림림에 전파 되도록 합니다. 예를 들어, 100개의 요청에 대해 limitRate(10)을 하는 것은 10개에 대해 최대 10번의 요청을 하도록 업스트림에 전파하게 됩니다. 이러한 형태에서 limitRate는 보충 최적화를 실제로 구현하고 있음을 유념하시기 바랍니다.
오퍼레이터들은 또한 보충하는 양을 튜닝할 수 있게 하는 변형들을 가지고 있으며, 그러한 변형들에서 lowTide로 언급 됩니다: limitRate(highTide, lowTide). lowTide의 값을 0으로 선택하는 것은 보충 전략에 의해 추가로 재형성 된 배치(batch)들 대신 highTide 요청의 엄격한 배치를 발생하게 합니다.
반면에 limitRequest(N)는 다운스트림 요청을 최대한의 최종 요청으로 감싸(caps)게 됩니다. 요청들을 N개 까지 합칩니다. 만약 하나의 요청이 N개를 초과하는 최종 요청을 만들지 않는 경우 해당 요청은 전체적으로 업스트림에 전파됩니다. 소스에 의해 해당 수량이 방출 된 후 limitRequest는 시퀀스 완료를 고려하고 onComplete 시그널을 다운스트림으로 보내고 소스를 취소합니다.
Programmatically creating a sequence
이번 섹션에서는 관련 있는 이벤트들(onNext, onError 그리고 onComplete)들을 프로그래밍적으로 정의 함으로써 Flux와 Mono를 생성하는 방법을 설명하겠습니다. 이러한 모든 메서드는 그들이 우리가 sink라고 부르는 이벤트를 트리거 하게 하도록 하는 API를 공개한다는 점을 공유하고 있습니다. 곧 살펴보겠지만, 사실 몇 가지 sink의 변형들이 존재합니다.
Synchronous generate
Flux를 프로그래밍적으로 생성하는 가장 단순한 방법은 generator function을 가지는 generate 메서드를 통하는 것입니다.
이것은 동기적이고(synchronous) 순차적인(one-by-one) 생성으로, sink는 SynchronousSink이고 이것의 next() 메서드는 콜백 요청 당 최대 한 번만 호출 가능함을 의미합니다. error(throwable) 또는 complete()를 호출할 수 있지만, 선택적인 부분입니다.
가장 유용한 변형은 아마도 sink를 사용할 때 다음으로 생성할 것을 결정할 수 있도록 상태를 저장하고 참조할 수 있게 해주는 것일 겁니다. 오브젝트 상태의 타입을 나타내는 <S>와 함께 BiFunction<S, SynchronousSink<T>. S>의 시그니처를 가지는 generator function을 확인할 수 있습니다. 최초의 상태로서 Supplier<S>를 제공하면, generator function이 각각의 단계에서 새로운 상태를 반환합니다.
예를 들어, int를 상태로서 사용할 수 있습니다:
Example of state-based generate
1 | |
{1} 최초 상태 값으로 0을 제공합니다.
{2} 무엇을 생성할지(3에 대한 곱셈)에 대해 선택하기 위해 상태를 사용합니다.
{3} 언제 멈출지를 선택하기 위해서도 상태를 사용합니다.
{4} 다음 호출(이번 단계에서 시퀀스가 멈추지 않는다면)에서 사용하기 위한 새로운 상태를 리턴합니다.
위 코드는 3에 대한 곱셈을 생성하며, 아래 시퀀스와 같습니다.
1 | |
또한 변형 가능한(mutable) <S>를 사용할 수 있습니다. 위 예제는 각 단계마다 변형시키는 단일 AtomicLong을 상태로서 사용하여 재 작성 가능합니다:
Mutable state variant
1 | |
{1} 이번에는 상태로서 변형 가능한 오브젝트를 생성합니다.
{2} 이 부분에서 상태를 변형합니다.
{3} 새로운 상태로서 동일한 인스턴스를 반환합니다.
만약 당신의 상태 오브젝트가 몇몇 리소스를 초기화하기 원한다면,
generate(Supplier<S>, BiFunction, Consumer<S>)변형을 사용하여 마지막 상태 인스턴스를 초기화 하세요.
Consumer를 포함하는 generate method를 사용하는 예제는 아래와 같습니다:
1 | |
{1} 다시 한 번, 상태로서 다수의 오브젝트르 생성합니다.
{2} 여기서 상태를 변형 시킵니다.
{3} 새로운 상태로서 동일한 인스턴스를 반환합니다.
{4} 이 Consumer 람다의 아웃풋으로 마지막 상태 값(11)을 확인할 수 있습니다.
상태가 데이터 베이스 커넥션을 포함하거나 프로세스의 마지막 과정에서 처리가 필요한 다른 리소스들이 있는 경우, Consumer 람다가 커넥션을 종료 시키거나 마지막에 처리 해줘야 하는 동작들을 다룰 수 있습니다.